{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
结合逻辑推理与内容计算实现面向学术网络的智能检索*
引用本文
聂卉. 结合逻辑推理与内容计算实现面向学术网络的智能检索*. 现代图书情报技术, 2013, 29(1): 22-29Nie Hui. Combining Logical Inference with Content-based Computing for Intelligent Retrieval in Academical Networks. New Technology of Library and Information Service, 2013, 29(1): 22-29 
Permissions
结合逻辑推理与内容计算实现面向学术网络的智能检索*
摘要
本体描述语言OWL-DL的表达能力局限于描述逻辑, 因不能挖掘推理实例间的关联而影响本体的实际利用率。针对这一问题, 研究基于SWRL的知识库推理机制, SWRL机制通过引入规则推理扩展本体知识库中的语义关联, 使隐性知识显性化, 推理结果更完善。该框架被用于解决面向学术资源网络的隐含知识发现问题, 同时融合内容计算来发掘学术文献间的主题关联。本文提出的方法及策略在原型系统中得以检验, 实验证明其合理性、可行性及有效性。
关键词:
本体推理; SWRL; 智能检索
Combining Logical Inference with Content-based Computing for Intelligent Retrieval in Academical Networks
Abstract
The expression ability of Ontology description language OWL- DL is restricted in description logic. The actual utilization regarding Ontology is impacted due to the implicated relations among Ontology individuals not being able to be detected. With regard to the issue, the SWRL-based inference mechanism for knowledge base is introduced, by which semantic relations implied in the knowledge base can be identified. Consequently, implicit knowledge is embodied explicitly and more extensive inference results can be available. The mechanism is employed to tackle the problem of implicit knowledge discovery of academic resources on the Web. Furthermore, the topic-specific relations for the academic resources are built on the basis of the content-based similarity measure. All regarding approaches are tested in the prototype indicating reasonability, feasibility and effectiveness of the scheme.
Keyword:
Ontology inference; SWRL; Intelligent retrieval
1 引 言
信息时代, 人们通过互联网获取信息。但传统检索策略不能真正了解用户的搜索意图, 网络资源因缺乏语义, “ 信息过载” 问题日益突出。要解决这一问题, 需从根本上提高信息源质量, 赋予资源机器“ 可理解” 的含义。
“ 本体” 作为信息的语义支撑, 提供了明确的语义定义方式。Web信息借助本体被理解, 使真正意义的语义检索成为可能。但随着应用的深入, 人们发现, 由于本体中许多重要知识隐性给出, 本体知识的实际利用率十分有限[1]。这是本体推理机制自身存在的缺陷导致的。本体描述语言(Ontology Web Language - Description Logical, OWL-DL)基于描述逻辑, 其推理局限于概念类属关系的判断, 对“ 如果… 则… ” 形式的规则推理无能为力[2]。例如, 检索任务中, 本体推理通常用于概念从属关系的判定和语义扩展, 语义相似度只探测概念间的关联性, 实例间的关系则无法获知。而复杂事物关联往往蕴含在实例对象中, 不能探知深层次关联意味着不能更好地认识利用。因此, 要使本体知识得以深层次应用, 还需更完善的推理机制。
SWRL是一种融合OWL和RuleML(Rule Markup Language)的规则描述语言, 能够驱使Horn-like规则与OWL知识库产生结合, 并通过扩展本体知识库来丰富推理内容, 发掘隐含信息。较之单纯的OWL-DL, 引入产生式规则的SWRL具备更强的知识描述能力, 能够克服OWL-DL的推理缺陷。为此, 本文针对学术资源检索任务中隐含知识的发现问题进行探索, 重点研究SWRL的推理机制和实现策略,并特别提出在推理机制中融合内容相似度计算识别学术文献内容关联的思路和方法。本文结合逻辑推理和内容计算两个方面来探索学术资源间的各种关联发现问题, 并付诸于实际应用, 共同服务于面向网络的学术资源的智能检索。
2 主要技术背景及相关研究
2.1 主要技术背景
OWL是W3C①推荐的网络本体描述语言。针对不同需求, 特别制定了OWLLite、OWL-DL和OWL-Full三种子语言, 本研究采用OWL-DL。OWL-DL具有较强的描述和推理能力, 推理机提供了三类服务, 分别是一致性检测(Consistency Checking)、分类(Classification)和类属指派(Realization), 统一归结为本体声明和类概念的逻辑一致性检测。因受DL描述能力所限, OWL-DL不能进行蕴含关联推导。SWRL扩展了OWL, 赋予OWL描述产生式规则的能力。利用SWRL, 基于DL的本体推理可融合规则推理, 实现更复杂的关系推演。例如, 推导个体实例p和s之间的关系, 则直接建立实例p和s间的推理规则[3]:
Person(?p)∧ hasSibling(?p, ?s)∧ Man(?s)→ hasBrother(?p, ?s)
形式上, SWRL为典型的产生式规则描述, 前件为一组假设的合取, 结论是属性或关联的声明。直观解释, 如果前件假设都成立, 则推论为真。SWRL被引入语义网解决OWL-DL不能充分表达复杂推理规则的问题, SWRL的作用使其逐渐成为语义网推理机制中不可缺少的因素。但目前还没有针对SWRL开发的推理机, SWRL推理往往借助其他推理引擎实现, 如Jess推理机。其核心是将规则融入本体一起推演, 依据新生成的本体, 丰富概念的语义关联, 完善本体知识库的内容。应用中, 只需根据实际需求在本体上建立相应的SWRL规则, 即可完成所需的推理服务。
2.2 相关研究
SWRL在智能推理方面独特的作用及意义, 使其在知识发现领域的应用日益广泛, 以生物医学和流程控制管理的应用为典型[3, 4, 5, 6, 7, 8, 9]。如, Beimel等[3]利用OWL和SWRL规范病患医疗记录的访问管理, OWL-DL推理被用于知识分类, 访问请求则依据SWRL规则推理进行智能化的应答处理。Yang等[5]采用OWL描述产品结构, 利用SWRL刻画产品设计中的约束条件, 以OWL结合SWRL的推理模式解决个性化产品设计中的问题。这类应用研究通常涉及关联复杂的事物的推理判断, 本体引入可规范领域的知识元, 本体框架下, 规则的引入赋予了描述知识元间复杂关联的能力, 融入SWRL推理的知识模型在解决这类问题的过程中发挥了重要的作用。在信息检索领域, 结合本体的SWRL推理往往针对特定检索任务[10, 11]。Wang等[10]是针对三维模型的检索系统, 利用SWRL给出识别对象的启发式原则。Cheng等[11]采用SWRL描述复杂的地理空间关系, 通过基于知识库的推理, 实现交通信息的语义检索。张巍[12]探讨了SWRL在医院问答系统中的应用, SWRL用来描述疾病, 症状与治疗之间的复杂关系。由于是基于知识库的知识推演, 所有研究均面向已经规范整合的结构化数据。事实上, 本体和SWRL技术只对规范化的结构型数据有好的表现, 目标信息源的形式与质量决定检索的实效。可见, 要使本体和SWRL得以深层次应用, 必须首先对目标信息源进行抽取提炼和规范整合, 这是不可缺少的基础环节。
本文主要针对网络学术文献的检索问题进行探讨。而网络学术资源形式多样, 数据未经规范处理, 单纯基于推理的检索策略并非特别适用于这类自由型文本资源的关联发现, 要借助SWRL来挖掘学术文献间隐含的各种关联, 实现智能化的检索。对本体的应用研究不仅需要考虑资源的规范及整合, 更要从研究对象的特质出发, 探求更适用的方法。事实上, 目前主流的搜索引擎大都依据内容计算量化排序关联网页, 内容计算在解决非结构化文本资源的发掘过程中发挥了重要作用。考虑到学术类资源的文本特性, 在针对结构化数据的推理机制中引入内容计算技术能更好地解决实际问题。因此, 在构建本体知识库的过程中, 笔者特别提出采用内容相似度计算来识别学术文献的内容关联, 并将其整合在基于规则的知识库推理检索策略中。从Pé rez-Agü era等[13]的工作中获取这一研究启发, 但目前尚未有具体的研究工作由此展开。本文从具体的检索任务入手探索这一检索策略的可行性, 目标是提高本体知识的利用率和灵活性, 使面向规范结构化数据的SWRL推理技术得到更广泛的应用。
3 基于SWRL推理机制的语义关联发现
3.1 面向学术资源网络的本体描述
时建立概念间的各种联系, 如Author-Paper间存在的论著关系“ Writed” 或“ Writed_by” 。概念实体的属性及显性关联, 直接取自初始信息源, 如合作者关系“ Co_author” 。隐性关联则依据内容计算或OWL推理获取。如:Author-Paper是作者和论著的关系, 从原始信息源中抽取Paper与 Author间的Writed_by关系, 通过在OWL中建立Writed_by与Writed的逆关系属性, 推理出Author与Paper间的“ Writed” 关系。更复杂的隐性关系, 通过设定相应的SWRL规则集建立, 如Author与ResearchTopic有关研究兴趣的关联“ Research_interest” 。对文本型的概念实例(如Paper), 借助更进一步的内容计算建立彼此间的相关性。
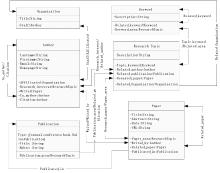
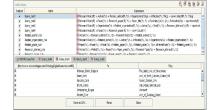
规范的数据描述框架是实现基于推理的智能化检索机制的基础环节。本文面向网络学术资源, 检索任务围绕学术资源。利用开放的Proté gé -OWL(Proté gé -OWL:一个开源的本体编辑和知识库构建框架http://protege.stanford.edu/overview/protege-owl.html)平台, 在领域专家的协助下, 构建了学术资源本体(OWL描述), 定义了围绕研究者(Author)、研究主题(Research Topic)、文献资源(Paper)等6个概念实体。本体描述框架如图1所示:
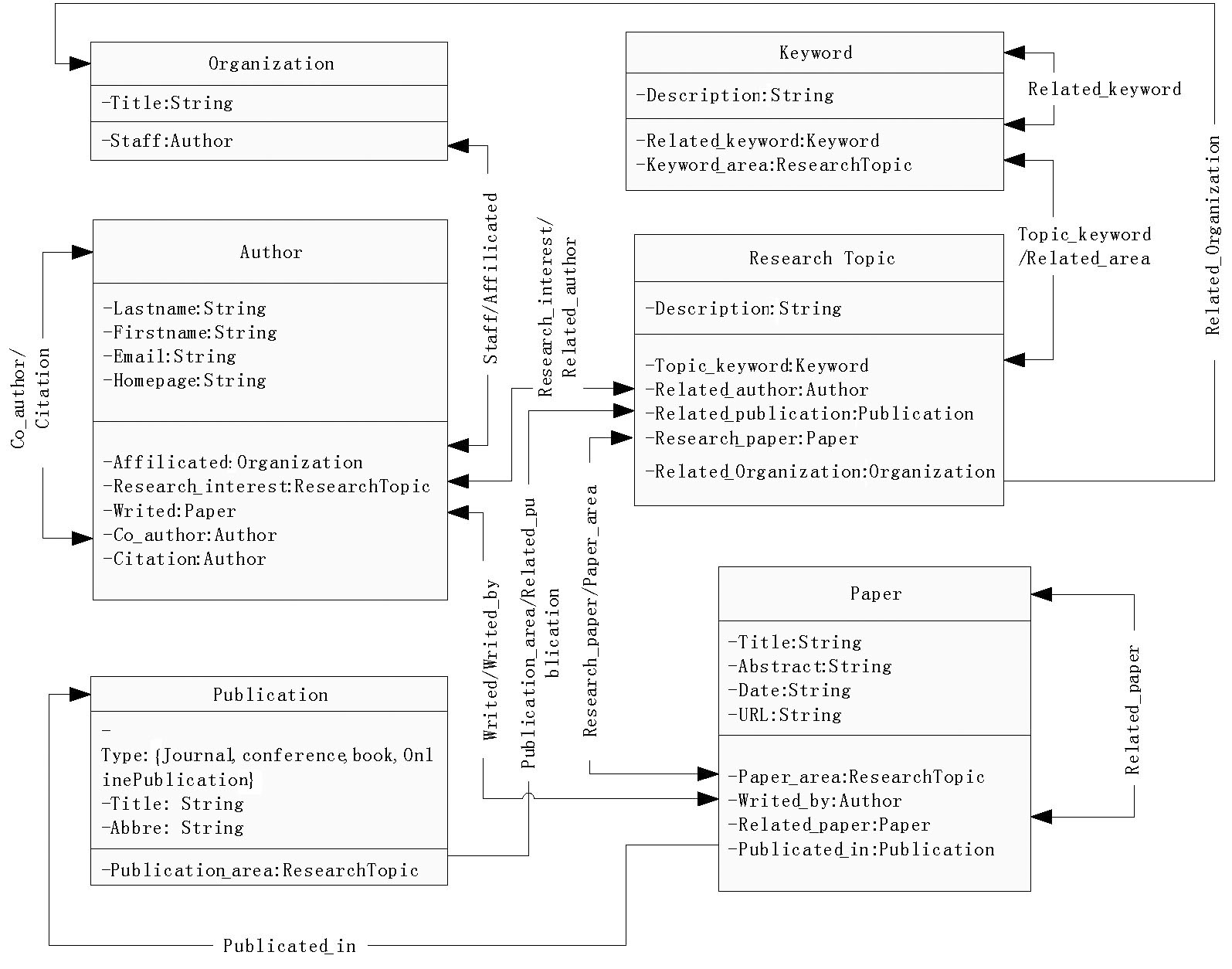 | 图1 学术资源本体的实体概念属性及关联描述框架 |
本体概念模型对获取学术资源所涉及的所有相关数据进行结构化的描述。6个主要的概念类及重要关联的描述如表1所示:
概念模型有机整合6类信息, 对每个概念类, 分别定义一组属性及关联。例如, 对于Author, 定义First-Name(姓)、LastName(名)、Email等一组静态属性, 同
| 表1 学术资源本体概念类说明及重要关联描述 |
时建立概念间的各种联系, 如Author-Paper间存在的论著关系“ Writed” 或“ Writed_by” 。概念实体的属性及显性关联, 直接取自初始信息源, 如合作者关系“ Co_author” 。隐性关联则依据内容计算或OWL推理获取。如:Author-Paper是作者和论著的关系, 从原始信息源中抽取Paper与 Author间的Writed_by关系, 通过在OWL中建立Writed_by与Writed的逆关系属性, 推理出Author与Paper间的“ Writed” 关系。更复杂的隐性关系, 通过设定相应的SWRL规则集建立, 如Author与ResearchTopic有关研究兴趣的关联“ Research_interest” 。对文本型的概念实例(如Paper), 借助更进一步的内容计算建立彼此间的相关性。
3.2 基于SWRL的推理机制的框架及实现
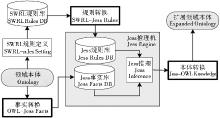
SWRL规则被引入本体推理, 结合本体知识, 推导学术资源本体中的隐性关联。SWRL推理机制框架如图2所示:推理实现采用Jess系统, 其核心由事实库、规则库、推理机三部分组成, 集成在Proté gé 中。
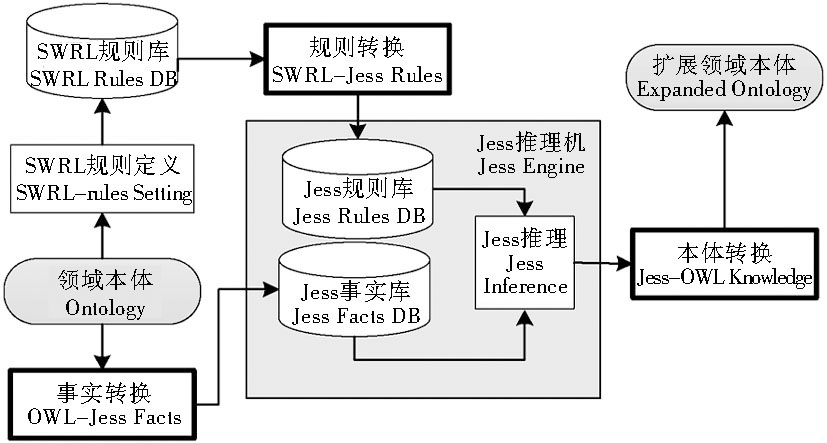 | 图2 基于SWRL的推理机制框架 |
可以看出, 推理以领域本体为起点, 依据隐性关联, 设定SWRL规则, 并通过OWL-Jess以及SWRL-Jess两个转换整合OWL本体和SWRL, 最后由Jess引擎执行推演。推演生成推断事实库, 进一步转换为本体的描述(Jess-OWL Knowledge)。因初始本体中隐性关系通过推理被发掘, 概念间的语义关联得以扩充, 新本体中, 隐性知识被显性地表示出来, 具体过程如下:
(1)OWL-Jess Facts 转换:OWL事实库到Jess事实库的转换。转换时, OWL本体中实例对象所属的类及其属性需要表达出来。 Jess特有的描述机制提供了表达OWL层次类的模式, 例如:
(deftemplate OWLThing (Slot name)) //定义Jess模板, 描述owl:Thing 类
(deftemplate Author extends OWLThing) //定义概念类Author为OWLThing的子类
(assert (Author (Francois_Fouss))) //声明类Author 的实例, 研究者Francois Fouss
(assert (Paper(Article_12_16))) //声明类Paper的实例, 文献Article_12_16
(assert (Writed Francois_Fouss Article_12_16)) //声明实例Francois Fouss 与Article_12_16之间的论著关系Writed
(2)SWRL-Jess Rules 转换:SWRL规则可直接转换为Jess规则。有关研究者研究兴趣“ Research_interest” 的推理规则转换。
SWRL :

(3)执行Jess推理机。Jess推理机基于事实库和规则库, 采用典型的前向产生式推理机制, 利用Rete算法完成推理计算。规则被触发时, 新生成的Facts被直接插入事实库, 并被用于新一轮的事实推演和规则激活。整个推演过程结束, 新生成的事实再次转换为基于OWL的知识描述。
3.3 结合内容相似度和SWRL推导发掘隐性关联
理论分析, 若实例属性及显性关系明确, 满足规则约束的隐性关系必然也已确定。但研究表明, 对自由文本型的学术文献, 单纯的规则推演并不能有效获知文献资源间的语义关联。文献间的关联主要反映在主题内容的相似度上。本文探讨的语义关联特指基于内容相似度的主题关联。由于内容相似度计算提取的是反映内容特征的词条, 词条的权重设计强调了文本描述的主题特征。经过处理, 对文本的内容描述提升至对其主题的描述, 则基于主题描述的相似度计算一定能够反映其主题的相关性。笔者曾采用关键词匹配进行内容关联的判定, 结果不甚理想。根本原因在于单纯的关键词不足以深刻描述资源的主题特征, 进而无法有效建立文献间的关联, 并影响到其他关系的判断。
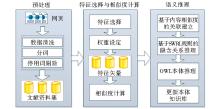
OWL和SWRL对规范的结构化数据有较好的表现, 但检索的效果效往往受制于目标知识源的质量。若要最大程度地发挥语义本体的作用, 信息源前期的提炼规范整合十分重要。因此, 对研究中涉及的文本型资源, 特别引入推理前利用主题内容相似度来构建针对文献关联的预处理环节, 以期获得更为理想的推理结果。因面向文本资源, 初始信息源遵循典型的自然语言处理(Natural Language Processing, NLP)流程, 如图3所示:
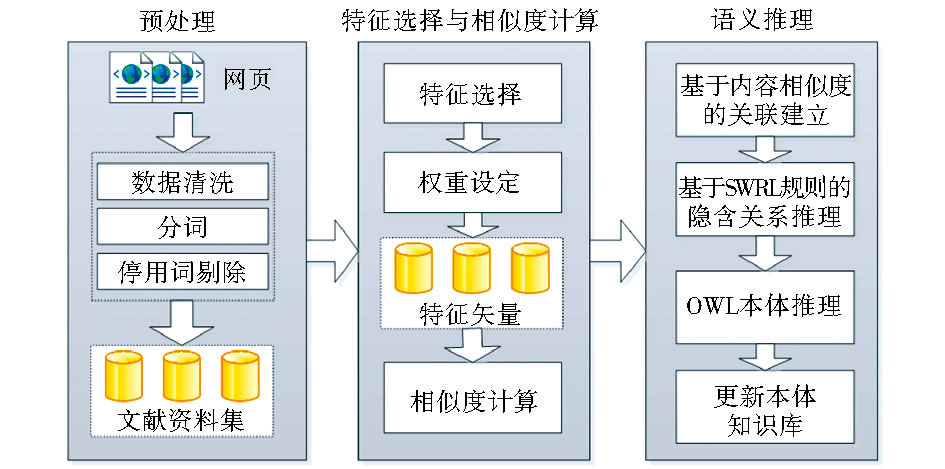 | 图3 结合内容相似度和SWRL推导发掘隐性关联系统流程 |
(1)预处理:数据清洗、分词、停用词剔除。数据清洗特别针对网页文献, 噪音信息(如标签)需要识别并剔除。
(2)特征选择:挑选最能有效表达文本内容的特征词条。简单的文档频率被选作评估函数。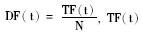 表示特征词条t出现的文档数, N表示文档的总数。预先设定两个阈值, DF低于最小阈值或者高于最大阈值的词从特征空间剔除。频率太低表明t不具代表性; 而频率过高, 则没有区分度。
表示特征词条t出现的文档数, N表示文档的总数。预先设定两个阈值, DF低于最小阈值或者高于最大阈值的词从特征空间剔除。频率太低表明t不具代表性; 而频率过高, 则没有区分度。
(3)权重的设定:特征权重衡量特征词条t在文中的重要度。采用词频-逆文档频率(TF-IDF), 并依据词条在文中的位置, 引入加权因子。记wij为特征词tj在文档di中的权重, 有:
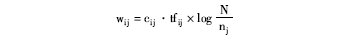
其中, tfij表示词条tj在文档di中出现的次数, nj表示包含词tj的文本数, cij反映tj在文本di中的位置。位置不同, tj对描述文本内容的贡献不同。cij定义如下:

标题和关键词中出现的特征词条更能反映文献的主题, 因而赋予较高权值。
(4)相关度计算:特征选取得到的文本特征集{ t1, t2, … , tm} , 则文献的向量空间模型VSM为dj=(wj1, wj2, … , wjm), 采用向量内积计算内容相似度。任意两篇文献d1=(w11, w12, … , w1m)和d2=(w21, w22, … , w2m)的相似度如下:
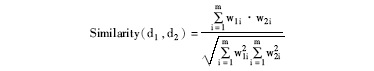
引入加权因子的词条权值wij整合了词条在文中的位置信息, VSM从结构和内容两方面整合了文献的主旨内容。Similarity(d1, d2)能够更加准确地量化二者关联。
(5)内容相似度关联的建立与推理
依据文献间的内容相似度为关联文档排序。对任意文献d1和d2, 依据如下原则确定彼此间的语义关联(ε 为关联阈值)。
If ( Similarity(d1, d2) ≥ ε ) Then Related_paper(d1, d2)
即如果d1和d2的内容相似度大于设定阈值, 则建立d1与d2的内容关联。同理, 若以基于关键词的特征向量表示ResearchTopic, 利用相似度计算同样能够发掘Paper与ResearchTopic间的内容相关性。设T为研究方向的向量描述, d为文献, 则Similarity(d, T)反映了文献d与研究方向T的关联度, 据此建立彼此的关系:
If (Similarity(d, T) ≥ ε ) Then Paper_area(d, T )
进一步, 依据基于内容计算的内容关联“ Related_paper” 及“ Paper_area” , 结合SWRL规则推理, 发掘概念实例间的隐性关系。例如:通过“ Related_paper” 关系, 推理未显性给出的文献间的内容关联, 定义规则RP_rule。
SWRL_RP_rule: Paper(?x)∧ Paper(?y)∧ Paper(?z)∧ Related_paper(?x, ?y)∧ Related_paper(?x, ?z )∧ differentFrom(?y, ?z)→ Related_paper (?y, ?z)
又如, 根据“ Paper_area” 推理Author的研究兴趣“ Research_interest” 。
SWRL_RI_rule: Author(?x)∧ Writed(?x, ?y)∧ Paper(?y)∧ Paper_area(?y, ?z)∧ ResearchTopic(?z)→ Research_interest(?x, ?z)
4 实验及评测
4.1 实验环境与技术实现
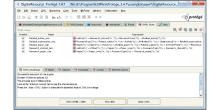
在Proté gé 3.4.7下构建学术资源本体DigitalResource.owl并对本体进行一致性检测。利用SWRL编辑器引入SWRL规则。Jess推理引擎集成在Proté gé 平台中。插件SWRLJessBridge执行SWRL规则到Jess格式以及OWL本体到Jess格式的转换。并依据转换后的事实库和规则库, 运行Jess, 推理产生新事实, 加入到本体知识库中, 如图4所示:
 | 图4 运行Jess 推理机 |
文本相似度计算采用独立函数设计, 词条权值依据词条所在位置进行权重处理。输入为文献集, 输出为具有文献内容关联属性的一组结构化文献元数据(XML), 引入本体实例库。
4.2 推理实例
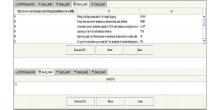
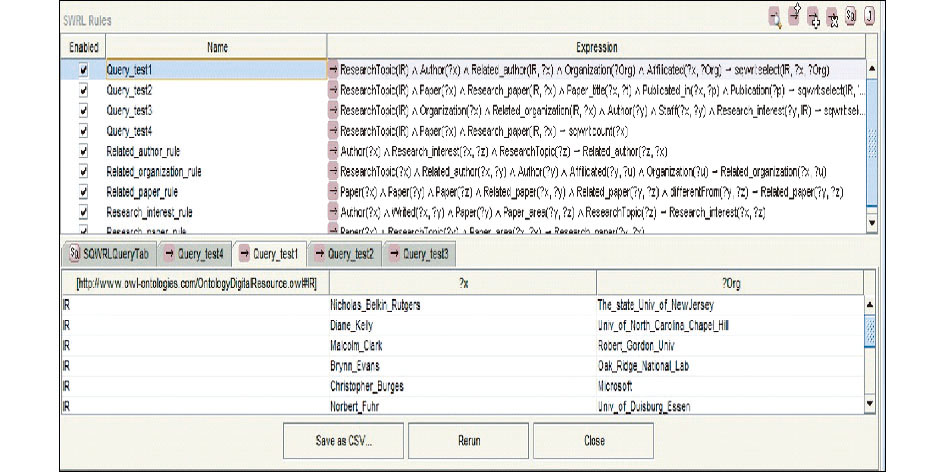
(1)检索问句Query-test1:在推理更新后的知识库中信息检索领域(IR)的研究专家的有关信息。
.
从应用角度看, 智能问答能够体现检索系统的推理能力。为此, 围绕学术本体知识库的核心概念, 笔者特别设计了一组问答形式的检索任务。采用SQWRL(Semantic Query-enhanced Web Rule Language)语言, 对本文提出的智能检索框架进行检测。SQWRL基于SWRL, 定义一组操作符专门用于构建面向OWL本体知识库的检索语句, 并结合SWRL规则一起运行。
对研究领域, 信息检索者主要关注领域相关的研究论文、研究者和研究机构。ResearchTopic (研究领域) 与Paper (文献资源), Author(研究者)及Organization(研究机构) 之间的关系隐藏在知识库中, 因为无法直接由知识源获取, 所以设定SWRL规则, 并借助已建立的显性关系及本体知识推理生成, 具体实例如表2所示:
| 表2 利用SWRL规则发掘隐性关系实例 |
ResearchTopic(IR) ∧ Author(?x) ∧ Related_author(IR, ?x) ∧ Organization(?Org) ∧ Affilicated(?x, ?Org) → sqwrl:select(IR, ?x, ?Org)
运行如图5所示:
 | 图5 Query-test1 运行截图 |
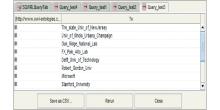
(2)检索问句Query-test2和Query-test4:检索IR领域的相关论文情况, 并统计论文总量。
ResearchTopic(IR) ∧ Paper(?x) ∧ Research_paper(IR, ?x) ∧ Paper_title(?x, ?t) ∧ Publicated_in(?x, ?p) ∧ Publication(?p) → sqwrl:select(IR, ?t, ?p)
ResearchTopic(IR)∧ Paper(?x) ∧ Research_paper(IR, ?x) → sqwrl:count(?x)
运行如图6所示:
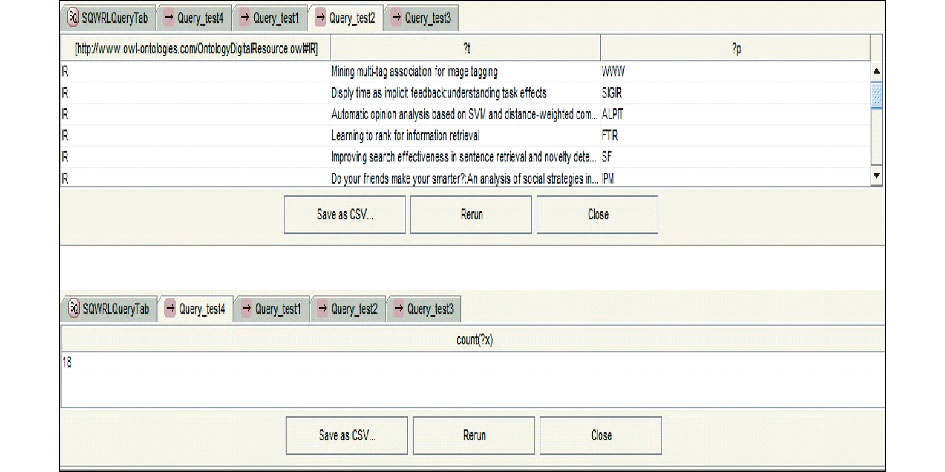 | 图6 Query-test2, Query-test4 运行截图 |
(3)检索问句Query-test3:检索IR领域的研究机构。
ResearchTopic(IR)∧ Organization(?x)∧ Related_organization(IR, ?x) ∧ Author(?y) ∧ Staff(?x, ?y) ∧ Research_interest(?y, IR)→ sqwrl: select(IR, ?x)
运行如图7所示:
 | 图7 Query-test3 运行截图 |
推理结论显示, 推理前ResearchTopic与Paper, Author及Organization之间的关系蕴含在知识库中。推理后融入规则和相似度计算的推理扩展丰富了本体知识库, 隐性关联显性化, 从而可以直接检索出研究领域与其他概念实例的相关性, 实现智能化检索。
4.3 实验评测及分析
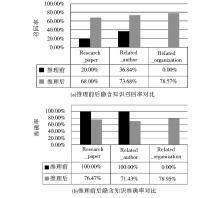
面向检索任务, 通过比较推理规则引入前后检索结果反映出的召回率和准确率来检验推理效果。实验数据源自微软学术搜索,共选取5个研究领域, 约150篇文献, 经过元数据的抽取、过滤与整理, 生成基于DigitalResource.owl测试用本体知识库。理论分析, 对知识库的检索, 显性关联明确的前提下, 检索结果也是明确的。由于引入SWRL规则推理, 知识库的隐性关联被显性化, 检索结果会更丰富, 检索召回率将明显提高。而准确率有赖于元数据的质量及规则的完备合理性, 需满足实际应用的要求。笔者推理实例的结论为例, 通过简单评测验证理论分析得出的结论。分析结果如图8所示:
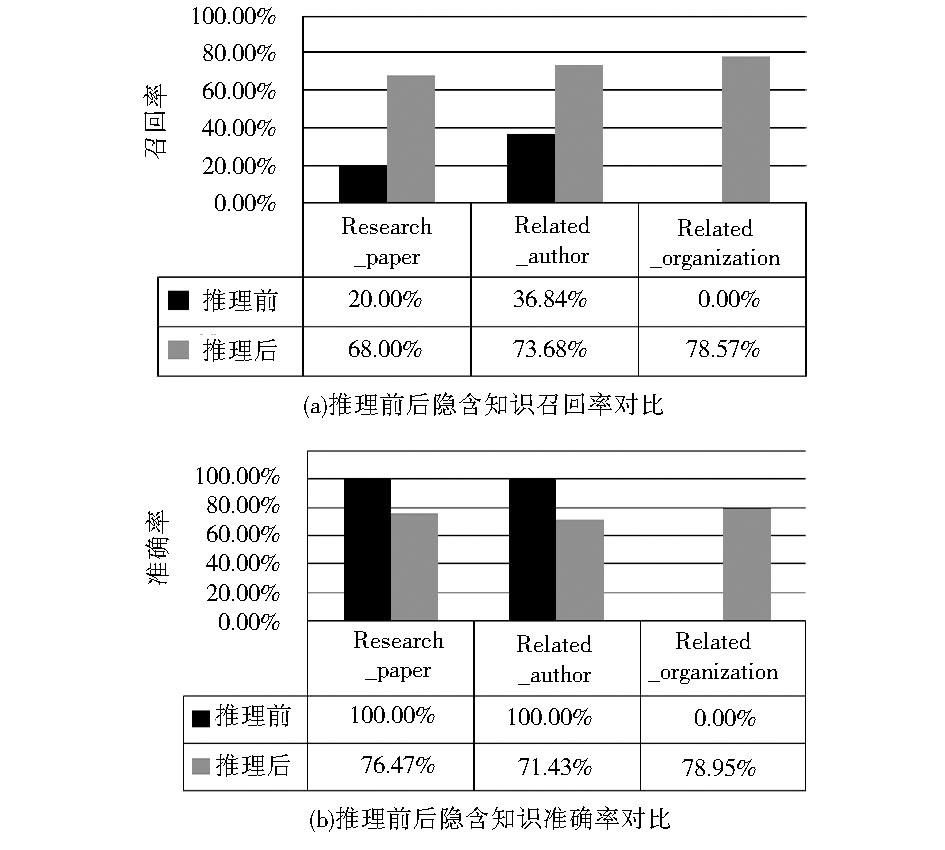 | 图8 推理前后对比 |
数据显示, 推理前大部分隐性关联未显性声明, 召回率普遍很低。特别是Related-organization, 该关系完全通过规则推理获取; 推理后, 规则推理出的事实丰富了知识库, 召回率大幅提高。这表明, 借助推理, 大量隐性知识被挖掘, 本体利用率提高。对于准确率, 推理前, 检索结果直接源自知识库, 结论明确; 推理后, 结论受规则完备性及内容相关性计算的影响, 出现误差。如, Research_paper关联的发现基于主题与文献内容的相似度, 主题描述不精确将直接影响关联的判断, 结果会受到较大影响。结论表明基于内容相似度的关联识别在推理过程中发挥了作用, 将该检索策略上升到概念层次, 会有更好的结果。
5 结 语
针对学术资源网的智能化检索任务, 在学术资源本体构建的基础上, 本文提出采用基于SWRL的知识库推理机制, 并融合矢量空间模型的文本相似度方法, 来解决面向学术资源网络中隐含关联的发现问题。基于SWRL的推理机制框架能够克服OWL-DL不能充分表达推理层面上复杂规则的局限, 通过引入SWRL规则推理, 使本体中的语义联系得以扩展, 推理结果更趋完善。另外, 对文本型资源, 特别提出逻辑推理结合内容计算的检索思路。内容计算能够自动辨别文献内容的语义关联, 由于内容的语义关联直接导致其他关联的推理判断, 可以提高内容计算的准确率, 对构建学术资源的知识模型及获得高质量推理结果起着重要的作用。
本文提出的方法和策略在原型系统中得以检验, 但本研究只是SWRL推理机制在文本型资源检索应用中的初步探索, 未来的工作将关注以下几点:
(1)内容相似度计算目前作为外部功能模块独立实现, 如何有机地整合到整个智能系统的设计中去;
(2)基于内容的相似度计算能够有效建立文本资源间的内容关联, 如果提升为基于概念的语义相似度计算, 是否能进一步提高检索的精度;
(3)本研究基于小规模的测试数据, 尚未出现推理实效的问题。但Jess是基于Java的CLISP推理机, CLISP为典型的基于产生式的前向推理引擎。作为前向推理系统, Jess用空间换时间, 推理过程产生大量的中间数据, 空间效率很低。推理实效受制于知识库规模及规则集大小。如何寻求优化策略, 满足实际应用的要求, 值得深入探索。
参考文献
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|